
Inteligencia artificial podría absorber todo el conocimiento escrito en Internet para 2026
En su carrera para convertirse en una suerte de dioses omniscientes, los sistemas de inteligencia artificial (IA) podrían consumir todo el conocimiento gratuito disponible en Internet tan pronto como en 2026, según advierte un nuevo estudio.

Crédito: MysteryPlanet.com.ar.
Los modelos de IA como GPT-4 o Claude 3 Opus dependen de los trillones de palabras compartidas en línea para volverse más inteligentes, pero nuevas proyecciones sugieren que agotarán el suministro de datos disponibles públicamente entre 2026 y 2032.
Esto implica que, para desarrollar mejores modelos, las empresas tecnológicas deberán buscar otras fuentes de datos. Estas podrían incluir la producción de datos sintéticos, recurrir a fuentes de menor calidad o —de manera más preocupante— acceder a datos privados almacenados en servidores que contienen mensajes y correos electrónicos.
«Si los chatbots consumen todos los datos disponibles y no hay avances en la eficiencia de los datos, esperaría ver una estancación relativa en el campo», dijo Pablo Villalobos, autor principal de un estudio publicado recientemente en el servidor de preimpresiones arXiv. «Los modelos solo mejorarán lentamente con el tiempo a medida que se descubran nuevos conocimientos algorítmicos y se produzcan nuevos datos de manera natural».
Los datos de entrenamiento impulsan el crecimiento de los sistemas de IA, permitiéndoles identificar patrones cada vez más complejos para integrarlos en sus redes neuronales. Por ejemplo, ChatGPT se entrenó con aproximadamente 570 GB de datos de texto, que suman alrededor de 300.000 millones de palabras, extraídas de libros, artículos en línea, Wikipedia y otras fuentes en Internet.
Los algoritmos entrenados con datos insuficientes o de baja calidad producen resultados dudosos. La sensible IA Gemini de Google —que recomendó agregar pegamento a las pizzas o comer piedras—, por ejemplo, obtuvo algunas de sus respuestas más polémicas de publicaciones en Reddit y artículos del sitio satírico The Onion.
Modelos hambrientos de datos
Para estimar cuánto texto hay disponible en línea, los investigadores utilizaron el índice web de Google, calculando que actualmente hay alrededor de 250.000 millones de páginas web con 7.000 bytes de texto por página. Luego, realizaron análisis del tráfico de protocolo de internet (IP) y la actividad de los usuarios en línea para proyectar el crecimiento de esta reserva de datos.
Los resultados revelaron que la información de alta calidad, extraída de fuentes confiables, se agotaría a más tardar en 2032, mientras que los datos lingüísticos de baja calidad se consumirán entre 2030 y 2050. Los datos de imágenes, por su parte, se agotarán entre 2030 y 2060.
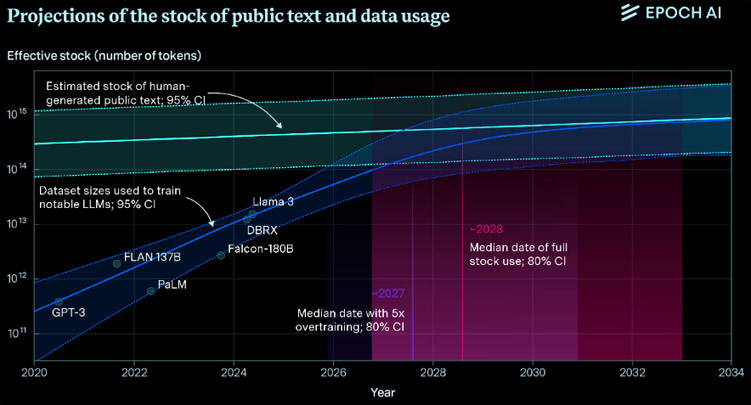
Crédito: EpochAI.org.
Se ha demostrado que las redes neuronales mejoran predictivamente a medida que aumentan sus conjuntos de datos, un fenómeno llamado la ley de escalado neuronal. Por lo tanto, es una pregunta abierta si las empresas pueden mejorar la eficiencia de sus modelos para compensar la falta de datos frescos, o si el cierre del grifo causará que las mejoras de los modelos se estanquen.
Sin embargo, Villalobos dijo que parece poco probable que la escasez de datos inhiba dramáticamente el crecimiento futuro de los modelos de IA. Esto se debe a que hay varias posibles estrategias que las empresas podrían utilizar para sortear el problema.
«Las empresas están intentando cada vez más usar datos privados para entrenar modelos, como el próximo cambio de política de Meta», añadió, refiriéndose al anuncio de la compañía de que utilizará interacciones con chatbots en sus plataformas para entrenar su IA generativa a partir del 26 de junio. «Si tienen éxito en hacerlo, y si la utilidad de los datos privados es comparable a la de los datos web públicos, entonces es bastante probable que las principales empresas de IA tengan suficientes datos para durar hasta el final de la década. En ese momento, otros obstáculos como el consumo de energía, el aumento de los costos de entrenamiento y la disponibilidad de hardware podrían volverse más urgentes que la falta de datos».
Otra opción es utilizar datos sintéticos, generados artificialmente, para alimentar los modelos hambrientos, aunque esto solo se ha utilizado con éxito en sistemas de entrenamiento en juegos, codificación y matemáticas.
Alternativamente, si las empresas intentan recopilar propiedad intelectual o información privada sin permiso, algunos expertos prevén desafíos legales.
«Los creadores de contenido han protestado contra el uso no autorizado de su contenido para entrenar modelos de IA, con algunos demandando a empresas como Microsoft, OpenAI y Stability AI», escribió Rita Matulionyte, experta en tecnología y derecho de propiedad intelectual y profesora asociada en la Universidad Macquarie, Australia, en The Conversation. «Ser remunerados por su trabajo puede ayudar a restaurar parte del desequilibrio de poder que existe entre los creativos y las empresas de IA».
Consumo de energía
Los investigadores señalan que la escasez de datos no es el único desafío para la mejora continua de la IA. Las búsquedas en Google impulsadas por ChatGPT consumen casi 10 veces más electricidad que una búsqueda tradicional, según la Agencia Internacional de Energía. Esto ha llevado a los líderes tecnológicos a intentar desarrollar startups de fusión nuclear para alimentar sus hambrientos centros de datos, aunque el método de generación de energía aún está lejos de ser viable.
Fuente: Epoch/LS. Edición: MP.


